This short guide shows the key steps in using BayesPy for variational
Bayesian inference by applying BayesPy to a simple problem. The key
steps in using BayesPy are the following:
Construct the model
Observe some of the variables by providing the data in a proper
format
Run variational Bayesian inference
Examine the resulting posterior approximation
To demonstrate BayesPy, we’ll consider a very simple problem: we have a
set of observations from a Gaussian distribution with unknown mean and
variance, and we want to learn these parameters. In this case, we do not
use any real-world data but generate some artificial data. The dataset
consists of ten samples from a Gaussian distribution with mean 5 and
standard deviation 10. This dataset can be generated with NumPy as
follows:
Now, given this data we would like to estimate the mean and the standard
deviation as if we didn’t know their values. The model can be defined as
follows:
where is the Gaussian distribution parameterized by
its mean and precision (i.e., inverse variance), and
is the gamma distribution parameterized by its shape and rate
parameters. Note that we have given quite uninformative priors for the
variables and . This simple model can also be
shown as a directed factor graph:
Directed factor graph of the example model.
This model can be constructed in BayesPy as follows:
This is quite self-explanatory given the model definitions above. We have used
two types of nodes GaussianARD and Gamma to represent Gaussian
and gamma distributions, respectively. There are much more distributions in
bayespy.nodes so you can construct quite complex conjugate exponential
family models. The node y uses keyword argument plates to define
the plates .
Now that we have created the model, we can provide our data by setting
y as observed:
>>> y.observe(data)
Next we want to estimate the posterior distribution. In principle, we could use
different inference engines (e.g., MCMC or EP) but currently only variational
Bayesian (VB) engine is implemented. The engine is initialized by giving all the
nodes of the model:
Now the algorithm converged after four iterations, before the requested 20
iterations. VB approximates the true posterior
with a distribution which factorizes with respect to the nodes:
.
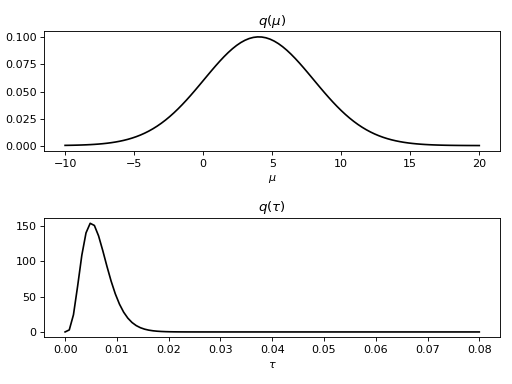
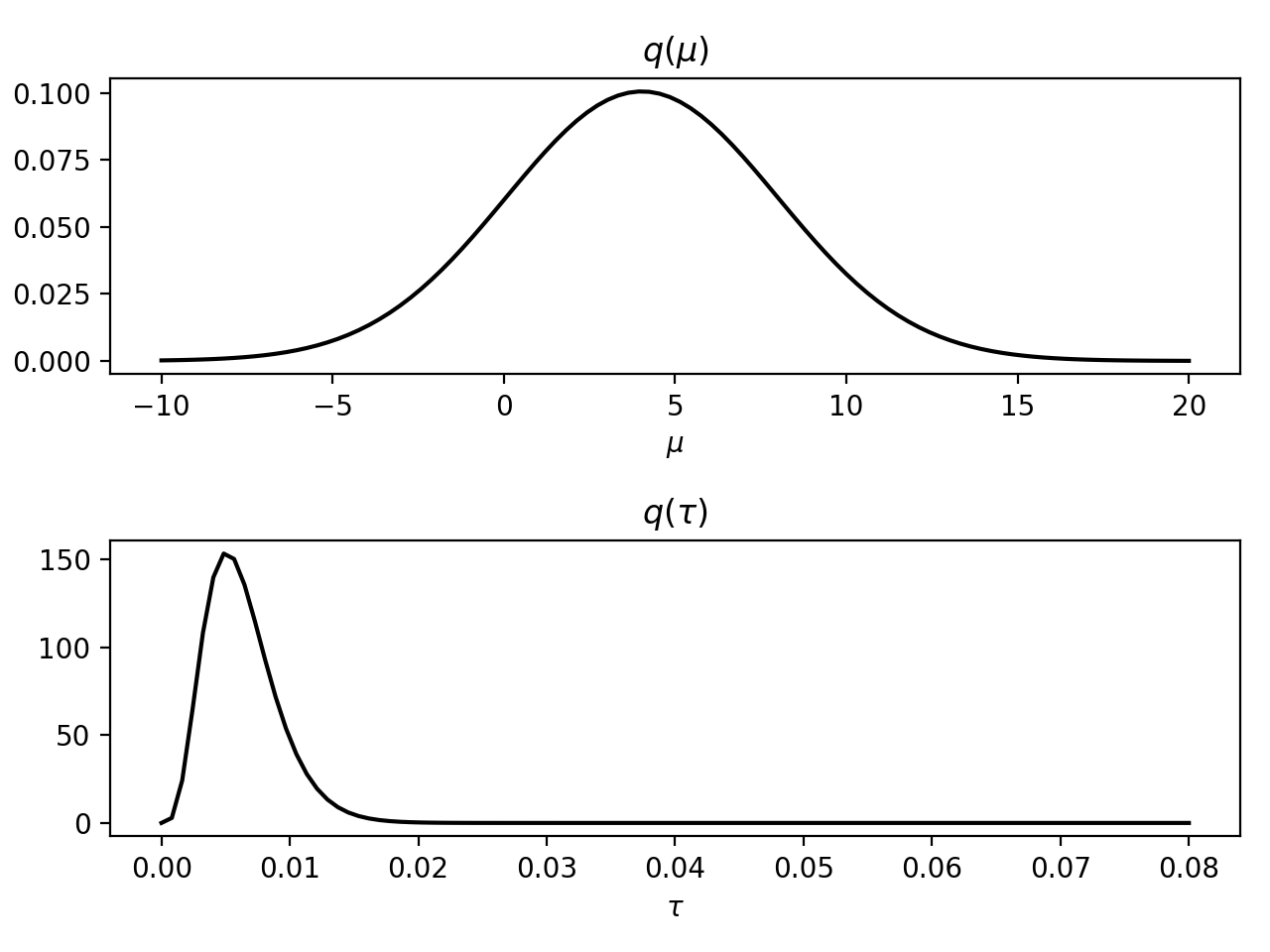
The resulting approximate posterior distributions and
can be examined, for instance, by plotting the marginal
probability density functions:
>>> importbayespy.plotasbpplt>>> bpplt.pyplot.subplot(2,1,1)<matplotlib.axes...AxesSubplot object at 0x...>>>> bpplt.pdf(mu,np.linspace(-10,20,num=100),color='k',name=r'\mu')[<matplotlib.lines.Line2D object at 0x...>]>>> bpplt.pyplot.subplot(2,1,2)<matplotlib.axes...AxesSubplot object at 0x...>>>> bpplt.pdf(tau,np.linspace(1e-6,0.08,num=100),color='k',name=r'\tau')[<matplotlib.lines.Line2D object at 0x...>]>>> bpplt.pyplot.tight_layout()>>> bpplt.pyplot.show()
This example was a very simple introduction to using BayesPy. The model
can be much more complex and each phase contains more options to give
the user more control over the inference. The following sections give
more details about the phases.

 is the Gaussian distribution parameterized by
its mean and precision (i.e., inverse variance), and
is the Gaussian distribution parameterized by
its mean and precision (i.e., inverse variance), and  is the gamma distribution parameterized by its shape and rate
parameters. Note that we have given quite uninformative priors for the
variables
is the gamma distribution parameterized by its shape and rate
parameters. Note that we have given quite uninformative priors for the
variables  and
and  . This simple model can also be
shown as a directed factor graph:
. This simple model can also be
shown as a directed factor graph: .
. with a distribution which factorizes with respect to the nodes:
with a distribution which factorizes with respect to the nodes:
 .
. and
and
 can be examined, for instance, by plotting the marginal
probability density functions:
can be examined, for instance, by plotting the marginal
probability density functions: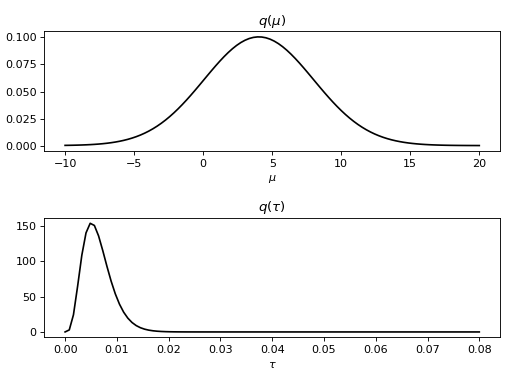
{kind=link}
{kind=link}