This example is a Jupyter notebook. You can download it or run it interactively on mybinder.org.
Linear regression¶
Data¶
The true parameters of the linear regression:
[1]:
import numpy as np
k = 2 # slope
c = 5 # bias
s = 2 # noise standard deviation
Generate data:
[3]:
x = np.arange(10)
y = k*x + c + s*np.random.randn(10)
Model¶
The regressors, that is, the input data:
[4]:
X = np.vstack([x, np.ones(len(x))]).T
Note that we added a column of ones to the regressor matrix for the bias term. We model the slope and the bias term in the same node so we do not factorize between them:
[5]:
from bayespy.nodes import GaussianARD
B = GaussianARD(0, 1e-6, shape=(2,))
The first element is the slope which multiplies x and the second element is the bias term which multiplies the constant ones. Now we compute the dot product of X and B:
[6]:
from bayespy.nodes import SumMultiply
F = SumMultiply('i,i', B, X)
The noise parameter:
[7]:
from bayespy.nodes import Gamma
tau = Gamma(1e-3, 1e-3)
The noisy observations:
[8]:
Y = GaussianARD(F, tau)
Inference¶
Observe the data:
[9]:
Y.observe(y)
Construct the variational Bayesian (VB) inference engine by giving all stochastic nodes:
[10]:
from bayespy.inference import VB
Q = VB(Y, B, tau)
Iterate until convergence:
[11]:
Q.update(repeat=1000)
Iteration 1: loglike=-4.080970e+01 (0.003 seconds)
Iteration 2: loglike=-4.057132e+01 (0.003 seconds)
Iteration 3: loglike=-4.056572e+01 (0.003 seconds)
Iteration 4: loglike=-4.056551e+01 (0.003 seconds)
Converged at iteration 4.
Results¶
Create a simple predictive model for new inputs:
[12]:
xh = np.linspace(-5, 15, 100)
Xh = np.vstack([xh, np.ones(len(xh))]).T
Fh = SumMultiply('i,i', B, Xh)
Note that we use the learned node B but create a new regressor array for predictions. Plot the predictive distribution of noiseless function values:
[13]:
import bayespy.plot as bpplt
bpplt.pyplot.figure()
bpplt.plot(Fh, x=xh, scale=2)
bpplt.plot(y, x=x, color='r', marker='x', linestyle='None')
bpplt.plot(k*xh+c, x=xh, color='r');
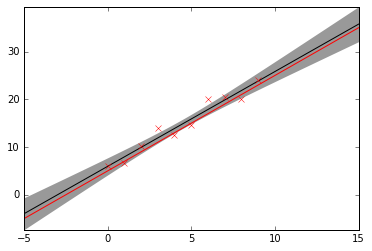
Note that the above plot shows two standard deviation of the posterior of the noiseless function, thus the data points may lie well outside this range. The red line shows the true linear function. Next, plot the distribution of the noise parameter and the true value, 2−2=0.25:
[14]:
bpplt.pyplot.figure()
bpplt.pdf(tau, np.linspace(1e-6,1,100), color='k')
bpplt.pyplot.axvline(s**(-2), color='r');
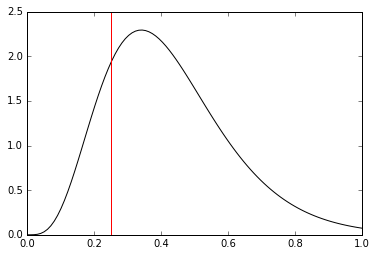
The noise level is captured quite well, although the posterior has more mass on larger noise levels (smaller precision parameter values). Finally, plot the distribution of the regression parameters and mark the true value:
[15]:
bpplt.pyplot.figure();
bpplt.contour(B, np.linspace(1,3,1000), np.linspace(1,9,1000),
n=10, colors='k');
bpplt.plot(c, x=k, color='r', marker='x', linestyle='None',
markersize=10, markeredgewidth=2)
bpplt.pyplot.xlabel(r'$k$');
bpplt.pyplot.ylabel(r'$c$');
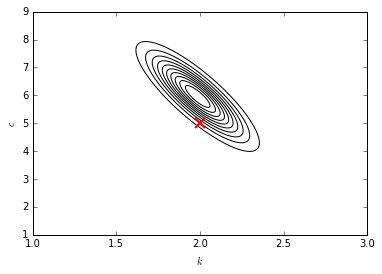
In this case, the true parameters are captured well by the posterior distribution.
Improving accuracy¶
The model can be improved by not factorizing between B and tau but learning their joint posterior distribution. This requires a slight modification to the model by using GaussianGammaISO node:
[16]:
from bayespy.nodes import GaussianGamma
B_tau = GaussianGamma(np.zeros(2), 1e-6*np.identity(2), 1e-3, 1e-3)
This node contains both the regression parameter vector and the noise parameter. We compute the dot product similarly as before:
[17]:
F_tau = SumMultiply('i,i', B_tau, X)
However, Y is constructed as follows:
[18]:
Y = GaussianARD(F_tau, 1)
Because the noise parameter is already in F_tau we can give a constant one as the second argument. The total noise parameter for Y is the product of the noise parameter in F_tau and one. Now, inference is run similarly as before:
[19]:
Y.observe(y)
Q = VB(Y, B_tau)
Q.update(repeat=1000)
Iteration 1: loglike=-4.130423e+01 (0.002 seconds)
Iteration 2: loglike=-4.130423e+01 (0.002 seconds)
Converged at iteration 2.
Note that the method converges immediately. This happens because there is only one unobserved stochastic node so there is no need for iteration and the result is actually the exact true posterior distribution, not an approximation. Currently, the main drawback of using this approach is that BayesPy does not yet contain any plotting utilities for nodes that contain both Gaussian and gamma variables jointly.
Further extensions¶
The approach discussed in this example can easily be extended to non-linear regression and multivariate regression. For non-linear regression, the inputs are first transformed by some known non-linear functions and then linear regression is applied to this transformed data. For multivariate regression, X and B are concatenated appropriately: If there are more regressors, add more columns to both X and B. If there are more output dimensions, add plates to B.